使用 TUN 设备配置 Linux 下的真·全局代理
突然想起来了自己的账号密码,年更博客更新啦!
为什么有这篇文章?
嗯,最近降本增笑,实在是没钱了,考虑给我 GIA 服务器降一个配置,但 GIA 机器上跑了不少服务,降掉配置以后就没办法同时跑这么多了服务了。
你可能会问,为什么不给这些服务迁到其他服务器上呢?
因为不少服务限定了我这个 GIA 小鸡 IP 的访问,迁移以后折腾起来好麻烦,而且,有些服务还是我本地需要访问的,兼顾访问速度,还是得 GIA 来加速。
再加上我有些东西是和 PT 有关的,而有些站为了防止羊毛甲骨文刷流,直接全局砍掉了来自甲骨文的流量,导致主站都上不去。
那你为什么本地不开代理呢?
好想法,如果这个项目折腾不成功我就打算这样干了。
我的服务器们
A:GIA 服务器,线路质量非常好,但配置很垃圾,1C1T 512M内存 15G硬盘 500Mbps@800G/月流量,别的配置低一点没事,最要命的是这个硬盘只有 15G,开了 SWAP,我的存储空间不够了,不开 SWAP,我的内存天天爆炸。
B:甲骨文服务器,ARM 架构 4C8T 24G内存 100G硬盘 4Gbps@10T/月流量。啥啥都好,就是这个网络太垃了,本地电信高峰期访问甲骨文就跟吃了屎一样难受。
BTW,你怎么知道我又给甲骨文注册成功了?
需求+构思
大概是,我想让 GIA 机器做甲骨文的全局代理,同时,GIA 机器还能将外网的端口的请求转发到甲骨文去。简单一点讲,是将 GIA 作为甲骨文的网关。
Internet -> GIA -> 甲骨文 #入站流量
甲骨文 -> GIA -> Internet # 出站流量
大概就是上面写的这样,和网关非常相似。
所以大概也许可能,只需要在 GIA 上开一个代理服务端,甲骨文上起一个客户端便可以解决我这个需求。
实践
服务端
最先想到的服务端启用代理的方法便是经久不衰的袜子5 sock5,从而自然而然就想到了用大名鼎鼎的 ss5 启动服务端,但这玩意属实不行,年龄比我都大、得装一大堆依赖、还很难配置。
经过一番查找,我找到了 Gost,看了下文档,这玩意有点强,但可惜我只用到里面的 socks5。
启动这玩意的方法也很简单,下载二进制以后,一行命令解决。
1 | gost -L :1080 |
对,就是这么简单。但我可不想让我的 GIA socks5 被别人扫到,不然按照 GIA 流量价格算,一夜之间我就欠下服务器商一套房了,所以我们需要携带密码启动。
1 | gost -L admin:123456@:1080 |
但是这样每次手动启动还是太不优雅了,所以发动了我的传统艺能,用 systemd 来管理这玩意。
1 | cat > "/etc/systemd/system/gost.service" <<EOF |
嗯,服务端便解决了。顺便着重提一嘴这两行:
1 | StandardOutput=append:/var/log/gost.log |
因为 gost 会输出大量日志,在运行一段时间以后你的 journalctl可能会吃掉大量大量内存,这两行的作用便是将日志重定向到/var/log/gost.log,这样 journalctl 就不会吃掉我太多内存了。
客户端
首先,Linux 下我知道的能代理全局流量的方式就是 路由表 + Tun 设备的组合,自然找软件肯定得找能接管 Tun 设备流量的软件。
首先想到的便是 Surge,转头一想,老刘没写 Linux 版本,遂转向使用 Clash,然后又想到了 Clash 的仓库已经删库了,而且我没有任何分流的需求,遂放弃 Clash。
最后我找到了 tun2socks。一看特性。
- 全局代理: 处理来自本设备的任意网络应用的所有网络流量并通过代理转发。
- 代理协议: 通过 HTTP/Socks4/Socks5/Shadowsocks 远程连接且支持鉴权。
- 跨平台性: 具有 Linux/macOS/Windows/FreeBSD/OpenBSD 特定优化的多平台支持。
- 网关模式: 作为第三层网关处理来自同一网络中其他设备的所有网络流量。
- IPv6 支持: 所有功能都可以在 IPv6 中工作,允许通过 IPv6 代理转发 IPv4 连接,反之亦然。
- TCP/IP 栈: 由来自 Google 容器应用程序内核 gVisor 的用户空间 TCP/IP 网络栈强力驱动。
嗯,完美。但这软件只能接管来自 Tun 设备的流量,并不会帮助你设置路由表、创建 Tun 设备等操作,所以我们需要自己来解决这部分了。
设置 Tun 设备
1 | ip tuntap add dev tun2 mode tun |
一行命令,创建 Tun 设备,然后我们就可以看到它了。
1 | root@oracle1:~# ip link show |
但它现在还没有 IP,所以我们还应该给他分配一个 IP,然后直接 ifup 启用它。
1 | ip -4 addr add 198.18.0.1/15 dev tun2 |
我们便可以在 ifconfig 里看到这个 Tun 设备了,它的 IP 也是我们分配的 IP。
1 | root@oracle1:~# ifconfig |
很好,接下来启动 tun2socks 试试。
结果我不贴了,反正肯定不是预期的结果,因为路由表还没设置,所有流量依然是走了你的主网卡出,Tun 网卡还在苦苦等待发送到它这里的流量。
初见路由表
Linux 有 0~255 共 256 张路由表,0 号对应 unspec 表,253,254,255 对应 default, main, local,当前系统的全部路由表可以在 /etc/iproute2/rt_tables 文件里查看。系统默认的表都有他们独特的作用:
0 号表 unspec,这张表可以理解为其他所有表的总和,其他所有表里的条目都会和 unspec 表中的条目有一一对应的关系,更简单的描述便是 unspec 软链了其他所有表的条目。如果你想看系统里全部的路由条目,看这张表就可以了。当然不要突然发神经给这个表清空了,清空你的网保准寄。255 号表 local,这张表存放了所有到达本机的路由,比如 127.0.0.1、你的网卡 IP 均会命中这张表里的条目。254 号表 main,看名字就可以知道,这张表便是最主要的路由表了,大部分查询都会命中这个表,而它也是 Linux 下的默认路由表——如果你在修改表的时候不指定表,则默认修改它。253 号表 default,一般是空的,是系统留给我们用的。
除了这些路由表以外,你还可以自己指定属于自己的路由表,编辑 /etc/iproute2/rt_tables 即可。
看看我们系统的路由表吧,用 ip route show table main 即可看到我们系统的主路由表了。
1 | default via 10.0.0.1 dev eth0 proto dhcp src 10.0.0.237 metric 1024 |
如何看懂这个路由表呢?
首先看第一列,操作系统会把一个 IP 包的目标地址和路由表第一列的网段进行匹配,如果发现匹配的行就按照那一行的路由规则进行转发,如果找不到匹配的,就按照 default 所在的行进行转发。一般来说,路由表里面能够列出来的网段都是电脑所在的局域网,例如上面的 10.0.0.0/24 就是我甲骨文的内网,一般来说只有对于这些局域网的地址操作系统才能准确知道应该怎么转发,对于其他情况,一般就要把包发给上级的路由器,让上级的专业路由设备来决定这些包怎么走。
第一列后,路由表的每一行都是由一连串的属性组成的:
dev xxx表示应该这个 IP 包应该从名为xxx网卡(interface)发出。via xxx表示这个 IP 包应该发往地址为xxx的网关 / 路由器并由后者进一步地路由。这一条一般在default规则中最常见,比如我上面的default via 10.0.0.1。scope link表示目标地址在链路层可以直达,即不需要通过其他设备进一步转发了。这一条对于 tun2socks 的配置倒不是很重要。src xxx表示这个 IP 包的源地址最好是xxx。这个属性只有在一个 IP 包还没有确定源地址(也就是刚刚发出)的时候才有效,如果一个 IP 包已经有了一个源地址,那么这条规则是不会去改的。linkdown表示这一行对应的网卡设备处于离线状态。proto xxx记录了这一行路由规则的来源。例如,proto kernel说明这一行是内核加的,proto dhcp说明这一行来源于 DHCP。metric xxx表示这一行路由规则的优先级,如果路由表里有好几行都能匹配目标地址,那么系统会按照metric较小的一行来转发。
初见路由规则
上面说了,Linux 中有多个路由表,如果一个包能够匹配多个路由表,那么这个包到底该使用哪个路由表路由呢?所以这就引出了路由规则,路由规则可以使用ip rule show 来查看。
1 | 0: from all lookup local |
冒号前的数字表示一条规则的优先级,可以取 0 到 32767 的整数,值越小优先级越高。from all 表示这条规则匹配所有源地址的 IP 包(all 也可以换成具体的 IP 或者 IP 段,类似的条件还有 to all),lookup local 表示去查 local 这张路由表。因此,上面 ip rule 的输出翻译成人话就是:
- 首先查
local这张路由表,如果查到有一行匹配就按照这一行走; - 如果
local表匹配不上,接着查main表; - 如果
main表也匹配不上,就查default表; - 如果
default表也匹配不上,这包就寄了。
尝试配置路由
我们现在已经有了一个名字叫 tun2 的设备,他的 IP 是 198.18.0.1,如何修改路由表和规则才能使得它接管所有流量呢?
首先想到的便是直接在 main 表里将默认路由换成 198.18.0.1,既然它可以将所有流量转发给我的上级路由器,那他当然也可以将流量转发到 Tun 设备的 IP。我们这样设置:
1 | root@oracle1:~# ip route add default via 198.18.0.1 |
嗯?不能有重复的 default 规则?那我们给原来的默认规则删掉再添加就好了呗?考虑到当前情况下删除路由,会导致系统完全没有可用的路由从而断网失联;
即使成功添加了路由,tun2socks 也没有启动,Tun 设备所接管的流量也没有地方去了。
所以需要先启动 tun2socks:
1 | tun2socks -proxy socks5://<账号>:<密码>@<代理服务器IP>:<代理服务器端口> -device "tun2" |
然后修改路由表:
1 | ip route del default && ip route add default via 198.18.0.1 |
敲完以后还是发现寄了,直接就是一整个的失联。重新审视一下,我们的路由表里只有针对 10.0.0.0/24 这个段的路由规则:10.0.0.0/24 dev eth0 proto kernel scope link src 10.0.0.237,默认规则已经被我们修改为了 default via 198.18.0.1,所以流量不管怎么跑,只要目的地不属于 10.0.0.0/24 这个段,那么这个包依然会被绕回到我们的 Tun 设备,然后耗尽 TTL 从而被内核丢掉,人话就是,出现死循环了。
那么如何解决这个问题?我们需要确保通过 tun2 设备发出的包依然走原地址,所以我们可以给 main 表复制一份塞到之前上文提到过的,系统留给我们的空表 default 内。
1 | ip -4 route show table main | grep -Ev '^default|linkdown' | while read ROUTE ; do |
对于这种重复的工作,我选择写一个 shell 脚本来解决。解释一下上面这个脚本的含义,列出所有 IPv4 的路由表,除了 default 条目和 linkdown 状态的条目,全部添加到 default 表中,然后添加一个去往 198.18.0.1 默认规则。
接下来通过配置路由规则将大部分流量切过去,不要忘记指定各个规则的优先级,不然规则写反了一样白搭:
1 | ip -4 rule add to <代理服务器IP> lookup main prio 10000 |
很不幸,SSH 依然爆炸了,所有流量都走到了代理服务器,包括我们的 SSH 流量,所以还需要让外部入站的流量全走直连,我们可以加上一句:
1 | ip -4 rule add from 10.0.0.237 lookup main prio 10001 |
所以现在我们的路由表和路由规则便是:
1 | # 路由表 main |
这样,所有走主网卡入站的流量都依然走 mian 表查询路由,Tun 设备出站到代理服务器的流量也走 mian 表查询路由,其他剩下的流量全走 default 路由到 Tun 设备,原始的 mian 表里的特殊路由也被完整保留到了 default 表当中。
这下可以启动 tun2socks 了。
1 | tun2socks -proxy socks5://<账号>:<密码>@<代理服务器IP>:<代理服务器端口> -device "tun2" |
嗯,工作完美,但还不够,仅算是能用。
初见 iptables
上面的配置依然有一些局限性:
- GIA 流量非常宝贵,针对大流量软件我需要让他直连怎么办?
- 针对特定 IP 怎么直连?
为了解决这些问题,我们需要 iptables 对网络做一些小小的调整。我暂时还没用过 nftables 所以别问为什么不用它
iptables 是 Linux 内核中 netfilter 的高级封装,netfilter 和路由表、路由规则共同组成了 Linux 的网络体系,如下图 (如果你看不到下图的话请挂个梯子):
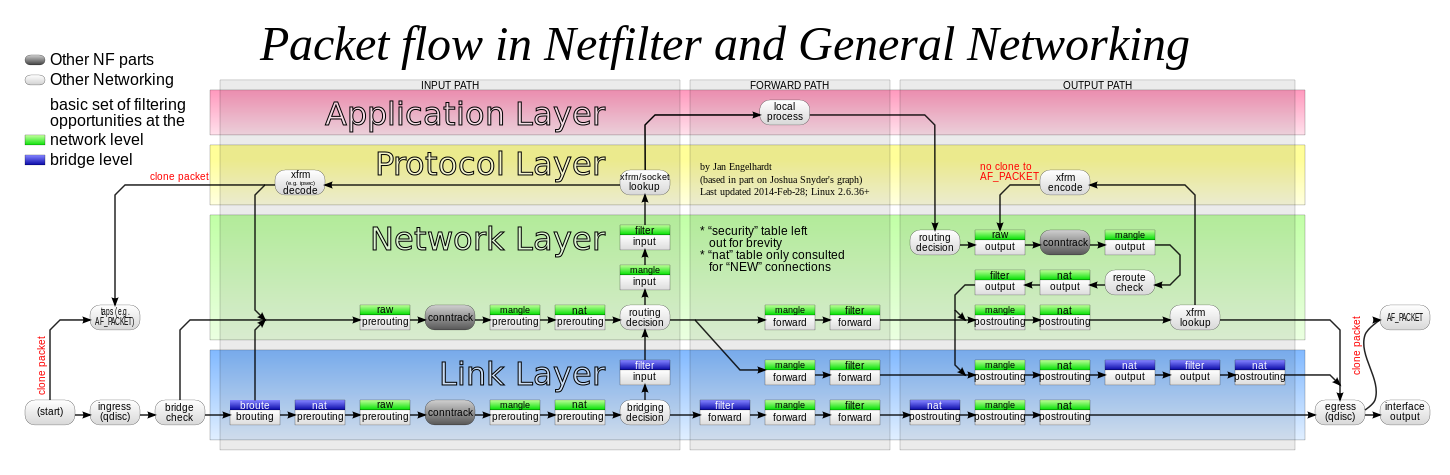
所以,怎么理解上面这张图呢?简化一下可以变成这样:
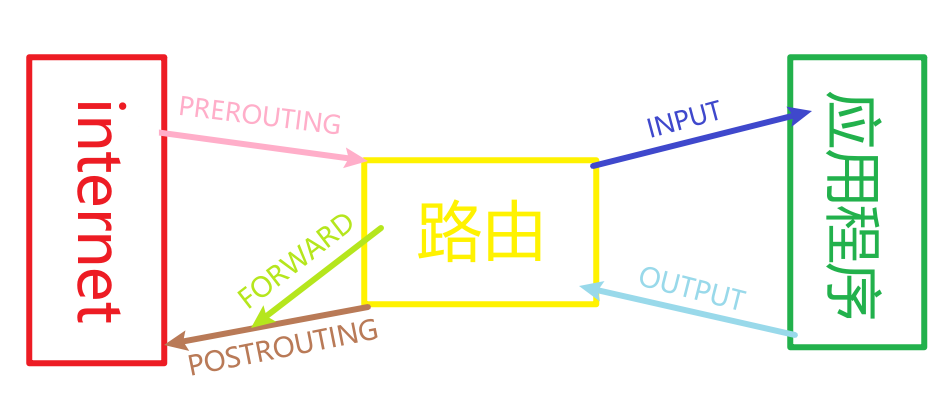
简单来说,五个链分别是这样的:
PREROUTING:数据包将在做出路由决断之前被该链处理;INPUT:已做出路由决断,且数据包终点属于本地的包将被该链处理;FORWARD:经过路由决断后目的地不是本地的包将被该链处理;OUTPUT:从本机发出的数据包在做出路由决断前被该链处理;POSTROUTING:已做出路由决断,数据包在传递给硬件之前被该链处理。
所有流量的路径将是这样的:
- 收到的、目的是本机的包:
PRETOUTING->INPUT - 收到的、目的是其他主机的包:
PRETOUTING->FORWARD->POSTROUTING - 本地产生的包:
OUTPUT->POSTROUTING
而这些链又被不同的表所包含,下面的表格展示了 表 和 链 的关系。横向是 表, 纵向是 链,X 表示 这个 表 里面有这个 链,例如,第二行表示 mangle 表 有 PRETOUTING 和 OUTPUT 两个 链。
| 表/链 | PREROUTING | INPUT | FORWARD | OUTPUT | POSTROUTING | 作用 |
|---|---|---|---|---|---|---|
| raw | X | X | 用于跟踪链接 | |||
| mangle | X | X | X | X | X | 修改包的 IP 头 |
| nat | X | X | X | X | 网络地址转换 | |
| filter | X | X | X | 作为防火墙使用 |
上面的作用都是我按照自己的理解概括的,每个表并不一定强制需要干这种活儿,比如说在 raw 表上直接拒绝入站请求,能省下不少资源,在一开始开始就拒绝这个请求,完全不需要经过后续一系列其他表的判断和内核处理,既节省 CPU 还节省内存,但如果你设置了 nat 表里的某些规则以后还在 raw 表里拒绝请求的话,那就有可能 boom。
回到正题,针对 GIA 流量非常宝贵,针对大流量软件我需要让他直连怎么办? 这个问题,我们可以用到 iptables 里的 mangle 表,在路由决断之前,为特定的包打上一个标签,然后在路由规则里匹配这个标签到主网卡,便可以实现直连了。那么如何实现呢?
1 | iptables -t mangle -A OUTPUT -m owner --uid-owner bypass -j MARK --set-mark 23333 |
解释一下这个命令,因为 OUTPUT 是在二次路由决断之前处理的,所以选择在这里打标记,将用户 bypass 的流量全部打上 23333 的标记;在路由规则里添加如果遇到被打上了 23333 标记的包就选择查询 mian 路由表。
而针对特定 IP 的直连问题,可以使用上面相同的方法来解决:将发往特定 IP 的包也打上相同的标记,让它走 mian 路由表查询即可:
1 | iptables -t mangle -A OUTPUT -d 1.1.1.1 -j MARK --set-mark 23333 |
塞入 Systemd 管理
由于我还需要设置路由表、路由规则、iptables规则,所以在编写 service 文件的时候不能简单的直接调用 tun2socks 的二进制,而是应该另起一个脚本。所以,我们可以这样干:
1 | cat > "/etc/systemd/system/xgpl.service" <<EOF |
简单解释一下各个字段的含义以及为什么要这样写:
Unit 区块
Description:一段关于这个服务的描述。
After:表示如果这些服务在系统启动的时候需要启动,那么本服务应该在它们之后启动;由于我们的实现严重依赖网络,尤其是 IPv4 地址,所以在系统启动的时候,我们应该等待这些服务启动后再启动本服务。
Before:在调用这个服务前,先调用本服务;一个习惯,在系统关机前,应该先停止本服务再关机,避免受到奇怪的影响。
Wants:表示弱依赖关系,列举出来的服务如果失败或者停止,本服务依然可以继续运行;原因上面讲过了,我们严重依赖网络服务。
Requires:表示强依赖关系,列出的服务如果失败或者停止,本服务也将一起下线;使用强依赖是因为如果需要重启网络服务,不跟着重启我们的服务的话,会导致 tun2socks 一直占用 tun 网卡无法释放,导致奇怪的 BUG(据我的观察,至少会导致 OOM)。
Service 区块
Type:
ExecStart字段将以fork()方式启动,此时父进程将会退出,子进程将成为主进程;这对于我们的服务可太合适了,tun2socks 作为主进程,脚本执行完毕便退出,最终只有一个 tun2socks 进程被 systemd 管理。
ExecStart:启动命令。
ExecStop:停止命令。
ExecReload:重启命令。
KillMode:当使用kill的时候,如何发送 SIG 信号。none 的含义是,没有进程会被强制杀掉(不发送SIGTERM、SIGKILL信号),只是执行服务的 stop 命令,毕竟我们还得清理一下路由表,不然当 tun2socks 下线的时候整个设备的网不直接寄了。
Restart:失败时重启模式。
User:运行本服务的用户;当然需要 root,不然怎么改上面的一大堆设置?
Group:运行本服务的用户组;顺手写了 root
Install 区块
WantedBy: 不太好解释,有点长,推荐你去看 这个。
好东西
终于折腾完了,顺带写了个一键脚本,仓库我塞这里了,欢迎 CV。https://github.com/X1A0CA1/xgpl
感谢这些参考资料:
https://unix.stackexchange.com/questions/506347/why-do-most-systemd-examples-contain-wantedby-multi-user-target
https://www.ruanyifeng.com/blog/2016/03/systemd-tutorial-part-two.html
https://arthurchiao.art/blog/deep-dive-into-iptables-and-netfilter-arch-zh/
https://www.frozentux.net/iptables-tutorial/chunkyhtml/index.html
https://www.lartc.org/LARTC-zh_CN.GB2312.pdf
https://danglingpointer.fun/2022/07/24/Tun2socks/
https://en.wikipedia.org/wiki/Iptables
https://github.com/xjasonlyu/tun2socks
https://github.com/ginuerzh/gost
https://www.ghl.name/archives/how-to-use-tun2socks-to-set-up-global-proxy-on-linux.html